<목차>
*Spring Framework를 사용하여 Web Application을 만들 수 있다.
*Web Application의 구조와 네트워크 통신에 대해 배우며 Web 전반에 대한 이해를 돕기 위한 네트워크 기초 지식
-네트워크 1
- 컴퓨터의 통신 방법
- 인터넷(Internet)
- 인터넷 프로토콜 IP(Internet Protocol)
- IP 방식의 문제점
-네트워크 2
- TCP(Transmission Control Protocol)
- UDP(User Datagram Protocol)
- PORT
-Web 기초
- DNS(Domain Name System)
- URI(Uniform Resource Identifier)
- URL(Uniform Resource Locator)
-용어 정리
- 프로그래밍 명명규칙(Casing)
- JSON
- Scale Up, Scale Out
- Stateful, Stateless
- Connection, Connectionless
<네트워크 지식이 필요한 이유>
1. 사용자가 요청을 했을 때 해당 요청에 대한 응답을 수행하는 프로그램인 서버를 개발하기 위해 필요하다.
2. 사용자의 요청에서 시작하여 우리가 만든 서버에 도착하고 다시 사용자에게 응답이 되돌아가는 흐름을 잘 파악하고 있다면 서버 개발에 도움이 된다.
3. 인터넷 브라우저(클라이언트)와 서버가 데이터를 주고받는 통신 방법인 HTTP(HyperText Transfer Protocol)는 결국 Web 기반에서 동작하기 때문에 네트워크에 대한 지식은 필수이다.
*Protocol(프로토콜) : 복잡한 인터넷 세상에서 컴퓨터와 컴퓨터끼리 데이터를 주고받기 위하여 정한 통신 규약
<Java와 IntelliJ IDE, Git 설치>
-대부분의 백엔드 웹 개발자는 IntelliJ 또는 Eclipse 사용
-이 세개를 사용
*IDE(Integrated Development Environment)
-소프트웨어 개발을 위한 통합된 환경
-코드 편집기, 디버거, 컴파일러, 자동 완성, 버전 관리 시스템 등 다양한 개발 도구들을 하나의 애플리케이션에서 제공하는 소프트웨어
-장점
- 코드 작성, 테스트, 디버깅을 한 곳에서 할 수 있어 개발 효율성을 크게 높여준다.
- 코드 자동 완성, 리팩토링 지원, 프로젝트 관리, DB 관리 등 다양한 기능을 제공한다.
네트워크 1
1. 컴퓨터들이 서로 통신하는 방법
-초기 컴퓨터 간 네트워크 연결은 물리적인 형태로 이루어졌음.
→USB 케이블과 같은 형태로 물리적으로 연결되면 서로 데이터를 주고받을 수 있음.
-하지만, 컴퓨터와 컴퓨터의 사이의 거리가 멀다면??
→인터넷을 통해서 데이터를 보내야함!!
2. 인터넷(Internet)
-인터넷 프로토콜 스위트(TCP/IP)를 기반으로 하여 전 세계적으로 연결되어 있는 컴퓨터 네트워크 통신망
-인터넷을 활용하여 멀리 있는 컴퓨터 간의 통신도 가능해졌다.
*해저 광케이블
-해저 광케이블로 물리적인 연결이 되어있다.

*인공위성
-인공위성을 통해 무선 통신도 가능하다.
*유/무선 방식으로 이름에 걸맞는 World Wide Web(WWW)가 구축되었다.
3. 인터넷 프로토콜 IP(Internet Protocol)
-인터넷이 통하는 네트워크에서 어떤 정보를 수신하고 송신하는 통신에 대한 규약을 의미
-우리가 흔히 알고있는 192.168.0.1과 같은 숫자는 IP가 아닌 IP에 필요한 고유 주소인 IP주소이다.
<데이터를 안전하게 전달하기 위한 최소한의 규칙>
-복잡한 인터넷 세상에서 데이터를 안전하게 전달하기 위해서는 최소한의 규칙이 필요하다.
*IP주소
-각 기기 간의 통신을 식별할 수 있는 전화번호
-최소한의 규칙을 지킬 수 있는 이유는 이 IP주소 덕분이다.
-인터넷 통신 시에는 지정한 IP 주소에 데이터를 Packet 이라는 단위로 전달
-IP(인터넷 프로토콜)를 사용하여 인터넷 세상에서 데이터를 통신할 수 있게 됨
*Packet
-패킷은 소스 IP, 대상 IP를 포함하고 있어서 어떤 컴퓨터에 데이터를 전송할 지 판별할 수 있다.
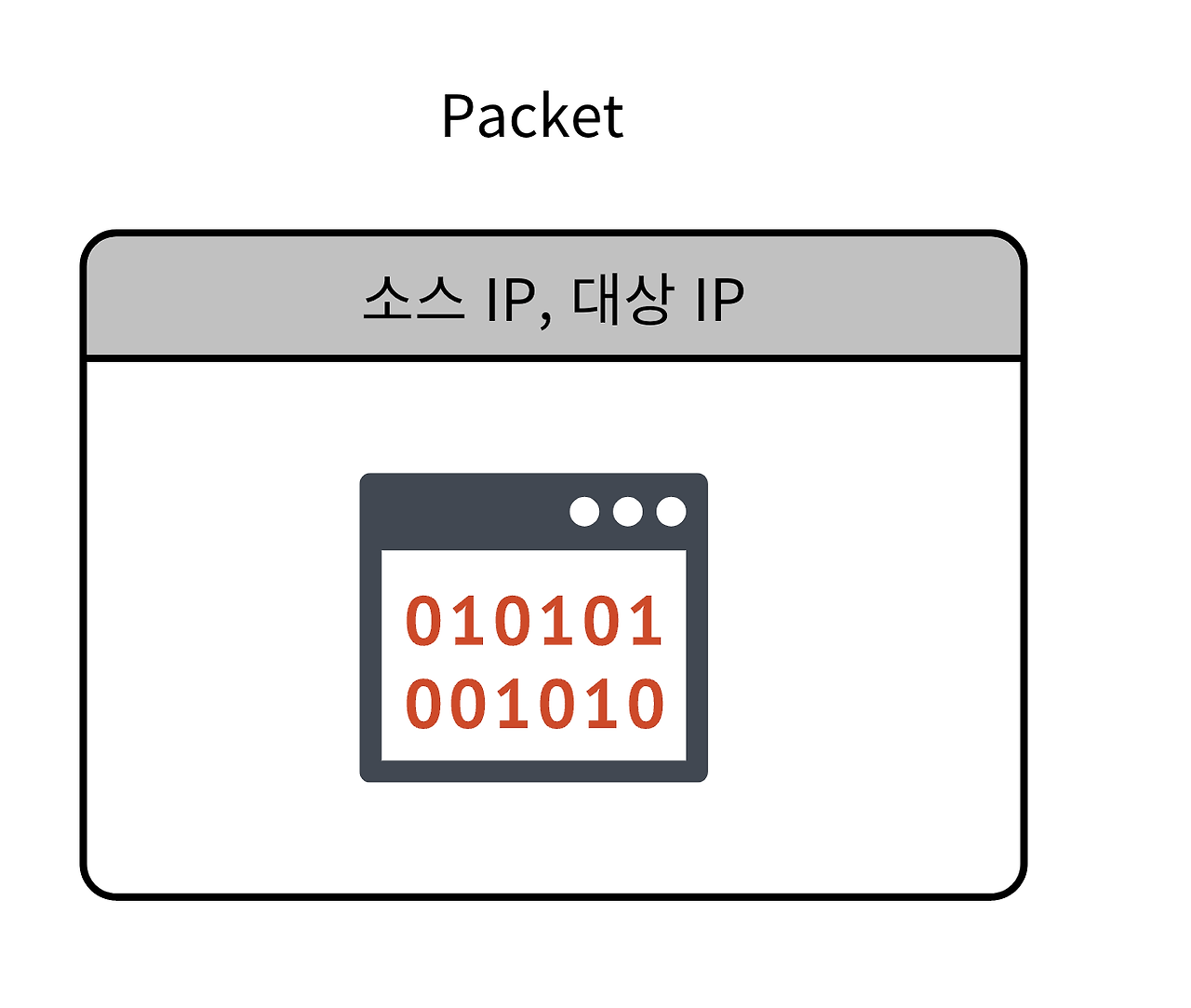
-소스 IP(출발지), 대상 IP(도착지)를 포함하고 있어서 어떤 컴퓨터에 데이터를 전송할지 판별할 수 있다.
-Packet은 크게 헤더, 페이로드, 트레일러(수신여부 포함)로 구분
-데이터를 주기만 하는 것이 아닌 받고 응답한다.
4. IP 방식의 문제점
*애플리케이션 구분
-대상 컴퓨터의 어떤 프로그램에서 사용될 데이터인지 구분할 수 없다.

*비연결성
-수신 대상의 현재 상태에 상관없이 데이터를 전송한다.

*비신뢰성
-패킷이 소실되는 경우가 발생한다.
-패킷의 손상여부를 송신, 수신측 모두 알 수 없다.


-패킷의 순서가 뒤죽박죽 섞여 들어오는 경우가 발생한다.
→용량이 큰 데이터의 경우 패킷이 여러개로 나뉘어져 전송된다.
→패킷이 손실되거나, 오류가 발생하여도 데이터의 재전송을 진행하지 않는다.
*위와 같은 문제점들을 해결해주는 것이 TCP 프로토콜 이다.
네트워크 2
1. TCP(Transmission Control Protocol)
-서버와 클라이언트 간에 데이터를 신뢰성 있게 전달하기 위해 만들어진 프로토콜
-IP방식에서는 패킷이 손실되거나 오류가 생겨도 데이터를 재전송하지 않는 등의 문제가 있었는데, TCP는 데이터를 신뢰성 있게 전달
*3 Way HandShake
-물리적으로 연결되는 것이 아닌 최소한의 논리적인 연결을 통하여 연결이 되었다고 가정하는 것

1. SYN 접속 요청
2. ACK 요청 수락 → ACK가 없다면 연결 실패
3. ACK → ACK 함께 데이터 전송 가능
*SYN(Synchronize)
-클라이언트가 서버에게 연결을 요청하는 첫 번째 단계
-클라이언트는 서버에게 "연결을 시작하고 싶다"는 의사를 나타내기 위해 SYN 플래그가 설정된 패킷을 전송
-패킷에는 시퀀스 번호도 포함되어 있고 데이터 전송 순서를 관리할 준비를 한다.
*ACK(Acknowledge)
-서버가 클라이언트의 SYN 패킷을 받고, 이를 확인했다는 신호를 보내는 단계
-서버는 클라이언트의 SYN 요청을 수락하며, 자신도 연결을 시작하고 싶다는 뜻을 담아 SYN 플래그와 함께 ACK 플래그가 설정된 패킷을 클라이언트에게 전송
-서버는 클라이언트의 시퀀스 번호에 1을 더한 값을 ACK로 응답
*데이터 전송 여부

-TCP를 통해 통신하면 데이터를 잘 받았다는 응답을 반환해줌
*패킷 순서

-패킷이 나누어져 오더라도 순서를 보장한다.
*TCP는 신뢰성이 있지만 연결하는 과정, 데이터 전송에 시간이 많이 소요된다.
-현재 단계 이상의 최적화를 하기 힘들다 => 최소한의 논리적인 연결이 필요하기 때문
-3way handshake 과정을 거치는 만큼 속도가 느리다.
2. UDP(User Datagram Protocol)
-비연결성, 비신뢰성 전송 프로토콜이다.
-TCP의 신뢰성 보장 기능은 많은 애플리케이션에 유용하지만 실시간 통신이나 스트리밍 애플리케이션에서는 빠른 전송이 중요해서 이를 충족하기 위해 UDP가 개발되었다.
-실시간 스트리밍서비스, 온라인게임, 화상전화 등
-특징 : 실시간성 보장 중요
*UDP의 특징
-IP방식과 거의 비슷하다.
→3way handshake를 하지 않는다.
→데이터 전송, 응답, 순서를 보장하지 않는다(=비신뢰성)
-추가적인 기능이 거의 없다.
→기능이 없고 연결을 하지 않는 대신 속도가 빠르다.
-IP와 차이점으로 PORT가 존재한다.
→TCP에도 PORT가 존재한다.
-데이터 무결성 검사
→체크섬(Checksum)을 포함하고 있다.
→잘못된 데이터가 전송되지 않도록 만들어준다.
3. PORT
-같은 IP 내세어 프로세스 구분을 하기 위해서 사용
→같은 IP에서 동시에 여러가지 프로그램이 실행되고 있다면 IP주소가 같은데, 패킷의 도착지를 PORT를 통해 식별
-현재 전송하고자 하는 패킷이 어떤 곳에 필요한 패킷인지는 IP와 프로그램 구분을 하기 위해 사용되는 PORT를 사용

-PORT는 아파트 호수와 같은 역할을 수행
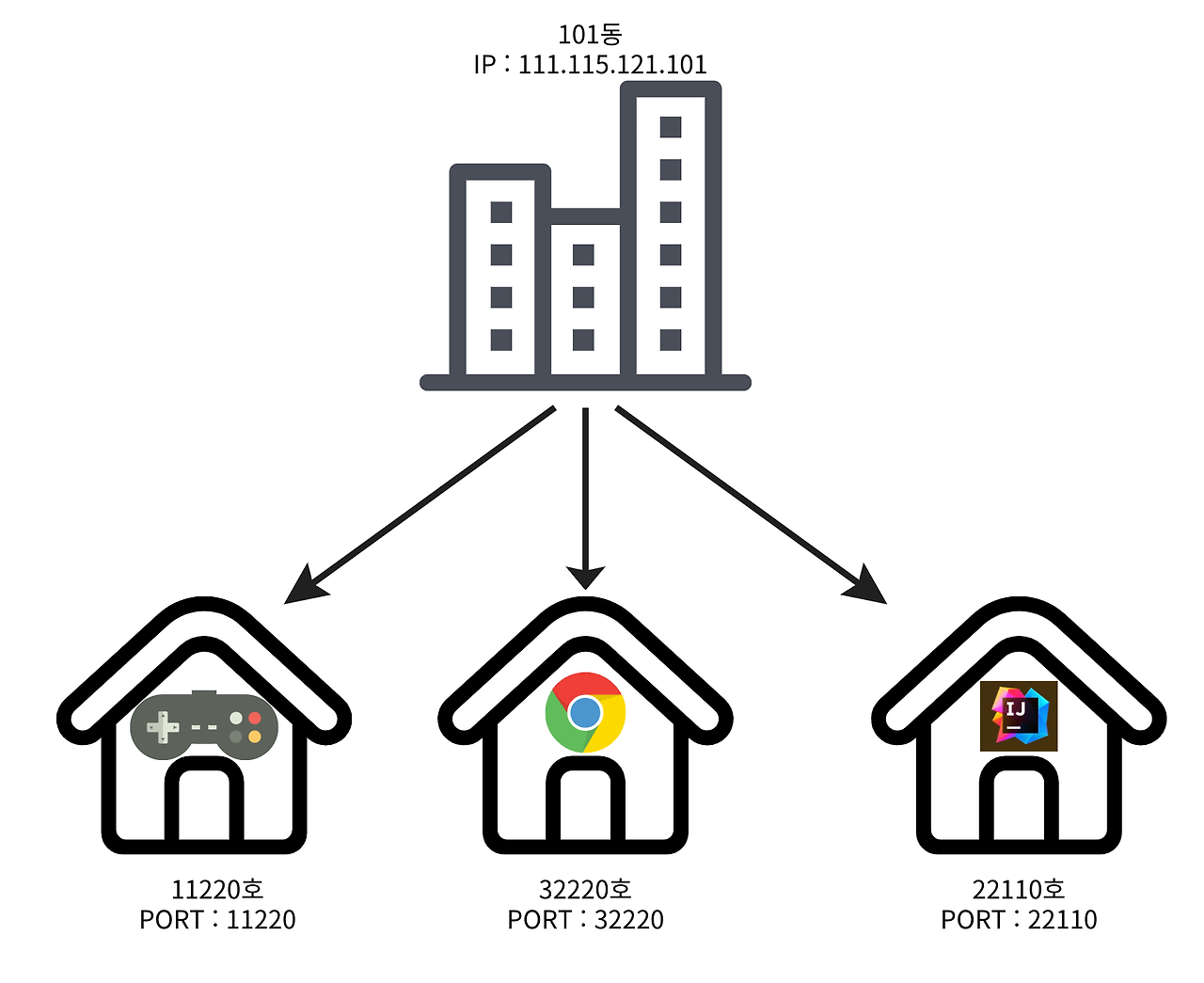
*TCP/IP Packet 구조
-소스 PORT, 대상 PORT를 포함

*자주 사용되는 PORT
-0~65535 할당 가능
-이미 사용되고 있는 포트(0~1023)
→국제 도메인 관리 기구에 의해 관리된다.
→사용하지 않는 것이 좋다.
- FTP : 20, 21(TCP)
- SSH : 22(TCP)
- TELNET : 23(TCP)
- SMTP : 25(TCP)
- DNS : 53(TCP/UDP)
- DHCP : 67(UDP)
- HTTP : 80(TCP)
- HTTPS : 443(TCP)
- RDP : 3389(TCP/UDP)
-실제 개발을 진행할 때 사용되지 않는 나머지 포트를 사용하여 개발
Web 기초
1. DNS(Domain Name System)
-도메인 이름과 IP 주소를 서로 변환하는 역할을 수행
-사람이 읽을 수 있는 도메인 이름을 컴퓨터가 읽을 수 있는 IP주소로 변환
*DNS가 나오게 된 이유
-컴퓨터 간의 통신을 위해서 IP주소가 필요하다.
→IP주소는 사이트마다 특징도 없고 길어서 외우기가 힘들다
→IP주소가 변경된다면 새로운 IP에 접근할 수 없다
-IP는 변경되는 주소이다.
→일반적으로 가정집에서 사용되는 IP는 유동IP다.
→만약 IP가 변경된다면 새로운 IP에 접근할 수 없다.
*DNS 동작 순서
1. 원하는 이름의 도메인을 구매 후, DNS 서버에 등록한다.
2. 도메인 명을 입력하면 DNS 서버는 IP 주소를 반환한다.

3. IP가 변경되면 DNS 서버에 등록된 IP주소만 바뀌면 된다.
4. 우리는 IP 주소의 형태가 아닌 도메인 이름 형태로 웹에 접속한다.
→일반적으로 URL이라 알고 있는것이 DNS를 활용한 예이다.
*ISBN : International Standard Book Number, 국제 표준도서
2. URI(Uniform Resource Identifier)
-인터넷 자원(Resource)을 나타내는 고유 식별자(Identifier)를 뜻한다.
-Uniform : 자원을 식별하는 통일된 방식을 의미
-Resource : 자원(페이지, 텍스트, 이미지, 동영상, 파일 등)을 의미
-Identifier : 식별자를 의미

*URI(Uniform Resource Identifier)
-인터넷 자원을 식별할 수 있는 문자열
-URI는 Locator, Name 혹은 둘 다 추가로 분류될 수 있다.
*URL(Uniform Resource Locator)
-자원의 위치를 의미 → 선생님이 있는 곳은 교무실
-일반적으로 도메인 주소로 알려져있다.
-프로토콜을 포함한다.(https)
*URN(Uniform Resource Name)
-자원의 이름을 의미 → 선생님
-리소스의 위치가 변경되어도 이름으로 리소스를 찾기 때문에 잘 동작한다.
-프로토콜을 포함하지 않는다.
-URN으로 실제 리소스에 접근하는 방법은 대중화 되어있지 않다.
*현재 대부분은 대중화된 URL을 사용하여, URI를 URL과 같은 의미로 사용한다.
3. URL(Uniform Resource Locator)
-프로토콜을 포함한 자원의 위치를 나타낸다.
*URL 구조
*scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment]
https://www.google.com:443/search?q=스파르타+코딩클럽
-scheme
→주로 프로토콜을 사용한다.
→웹에서는 http, https, ftp를 주로 사용한다.
→참고 : https = http + 보안(Secure)
-user[:password]
→사용자 정보
→URL은 보안에 취약하여 사용하지 않는다.
-host[:port]
→호스트명 : 도메인 명(www.google.com) 또는 IP 주소를 직접 사용한다.
→http : 80, https : 443 포트 사용
→포트는 일반적으로 생략한다.
-[/path]
→리소스의 경로
→계층 구조로 구성되어있다.
→프로토콜://쇼핑몰주소/products/macbookPro
→https://camp.sparta.kr/backend
-[?query]
→key=value 형태로 구성된다.
→Query Parameter, Query String 이라고도 한다. (둘 다 같은말)
→?로 시자되고 &로 구분된다.
→?key1value&key2=value&key3=value
-[#fragment]
→html 내부 북마크 등에 사용한다.
→전달받은 URL로 접속 시 특정 위치(fragment)로 이동할 수 있음
→http://www.google.com/index.html#image
*URL 방식의 한계
-자원의 위치를 변경하면 기존 URL은 사용할 수 없다.
-브라우저 검색창에 어떤 홈페이지를 검색하면 사이트가 노출된다.
→만약 이 주소를 바꾼다면 기존 경로를 아는 사람들은 검색 페이지의 URL이 업데이트 되지 않으면 페이지를 찾을 수 없다.
-이러한 한계를 극복하기 위해 URN이 등장
*브라우저에 URL을 입력하면 어떤 순서로 요청이 흘러가는지 확인
1. URL을 입력한다.

2. DNS 서버를 조회하여 www.google.com에 해당하는 IP 주소를 응답받는다.
-포트 번호는 생략되어있다.
-https에서 사용되는 PORT는 443이다.

3. 웹 브라우저에서 HTTP 요청 메세지를 생성한다.
-~을 검색해줘! 와 같은 의미

4. 요청 패킷(HTTP 메세지가 포함되어 있다)을 구글 서버로 전송한다.

5. 구글 서버에서 HTTP 요청 메세지를 기반으로 응답 HTTP 메세지를 만들어 응답한다.
6. 응답패킷 도착 → HTML이 응답으로 온다.
-응답 결과가 브라우저에 그려진다.
용어정리
1. 프로그래밍 명명 규칙(Casing)
-프로그래밍에는 각각의 언어, 환경에 알맞는 명명 규칙이 존재
*snake_case
-Python이나 DB Table, Column에 사용된다.
-문자와 문자 사이를 _언더바로 이어준다.
-모든 단어는 소문자이거나 대문자이다.
*camelCase
-Java, JavaScript, TypeScript에서는 변수, 함수, 메서드 이름을 만들 때 사용한다.
-문자와 문자 사이를 대문자로 이어준다.
*PascalCase
-대부분의 프로그래밍 언어에서 클래스 이름을 지정하는 데 파스칼 케이스가 사용된다.
-문자의 처음 시작을 대문자로 한다.
-문자와 문자 사이를 대문자로 이어준다.
*kebab-case
-문자와 문자 사이를 - 대시로 이어준다.
-모든 단어는 소문자이다.
*Java의 명명법
| 종류 | 설명 | 예시 |
| project 프로젝트, 레파지토리 |
대/소문자 구분 없이 시작 | MyProject |
| package 패키지 |
소문자 시작 | com.jy3574.blog |
| class 클래스 |
대문자 시작, 명사 사용, PascalCase | class Person; class Car; |
| interface 인터페이스 |
대문자 시작, 형용사 사용, PascalCase | interface Runnable; |
| method 메서드 |
소문자 시작, 동사 사용, camelCase | add(); calculate(); |
| variable 변수 |
소문자 시작, camelCase | int number; String inputNumber; |
| constant 상수 |
대문자로 시작, 문자와 문자사이는 언더바 _로 구분 | static final int MAX_COUNT = 999; |
2. JSON
-클라이언트와 서버가 통신할 때 사용하는 데이터 양식
-클라이언트와 서버가 사용하는 언어에 관계 없이 통일된 데이터를 주고받을 수 있도록 만들어줌
-과거 웹 초기 시절 사용된 XML은 헤더와 태그 등 여러요소로 가독성이 떨어지고, 불필요한 용량을 잡아먹는다는 단점이 있어 이에 대응해 간결하고 통일된 양식인 JSON을 사용
-JSON은 사람, 기계 모두 이해하기 쉬우며 용량이 작다.
-XML을 대체해서 데이터 전송 등에 많이 사용한다.
-전세계 공통어로 영어를 사용하는 것 처럼 Web에서는 JSON(JavaScript Object Notation)을 공통어로 사용한다.

-클라이언트 to 서버의 통신에 JSON을 사용한다.
-서버 to 서버의 통신에도 JSON을 사용한다.
*MSA(MicroService Architecture)
-아주 작은 단위로 서비스를 잘게 나누어 운영하는 아키텍쳐
-해당 아키텍쳐를 가지게 되면 구성된 애플리케이션마다 어떠한 언어를 사용하는지에 상관 없이 JSON 형태로 통신을 하기 때문에 서로 통신을 할 수 있다.
https://www.sktenterprise.com/bizInsight/blogDetail/dev/2714
MSA와 DevOps를 적용하여 상용 서비스 출시를 위해 힙(Hip)한 기술 모두 사용해보기 | 개발자 Story | S
현재 2개의 상용플랫폼을 개발/운영하고 있습니다. 블록체인 기반 DID/전자증명 플랫폼 ('21.3월 상용완료) SKT 통합 Digital Asset 서비스를 위한 모바일지갑 플랫폼 ('22.1월 상용 예정) MSA, Kubernetes,
www.sktenterprise.com
*JSON 구조
{
"user" : [
{
"first_name" : "jy",
"last_name" : "Kim",
"age" : "90",
"phone_agree" : "false",
"hobby" : ["TV","Sports"]
},
{
"firstName" : "sparta",
"last_name" : "Team",
"age" : "300",
"phone_agree" : "true",
"hobby" : ["Spring","Node"]
}
]
}
-snake_case, camelCase 모두 사용 가능하다.
→우리가 만드는 Application 내에서 변환해주는 무엇인가가 있다.
-key-value 형태로 구성되어 있다.
-null, number, string, array, object, boolean 형태의 데이터를 사용할 수 있다.
3. Scale Up, Scale Out
-서버의 성능 향상을 위한 두가지 방법이다.
*Scale Up -수직적 확장
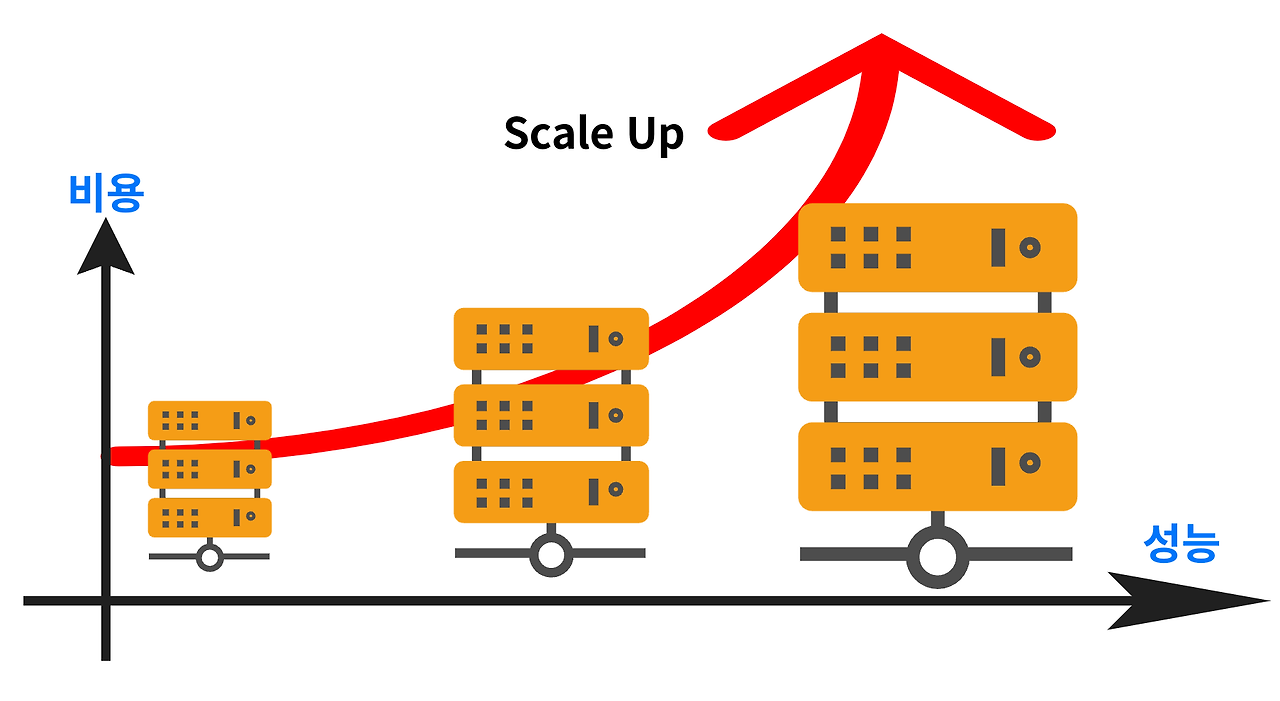
-단일 서버의 하드웨어의 사용을 높인다. (CPU, Memory 등의 스펙을 높인다.)
-요청에 대한 처리를 더욱 빠르게 할 수 있도록 만든다.
-성능이 좋아질수록 비용도 올라간다.
*Scale Out -수평적 확장

-같은 사양의 서버(인스턴스)를 여러 대 배치한다.
-동시에 더 많은 사용자 요청을 처리할 수 있도록 만든다.
4. Stateful, Stateless
-클라이언트와 서버간의 통신 상태(state) 유지 여부에 따라 나뉘는 특성
*Stateful -상태유지
-클라이언트의 상태를 유지한다.
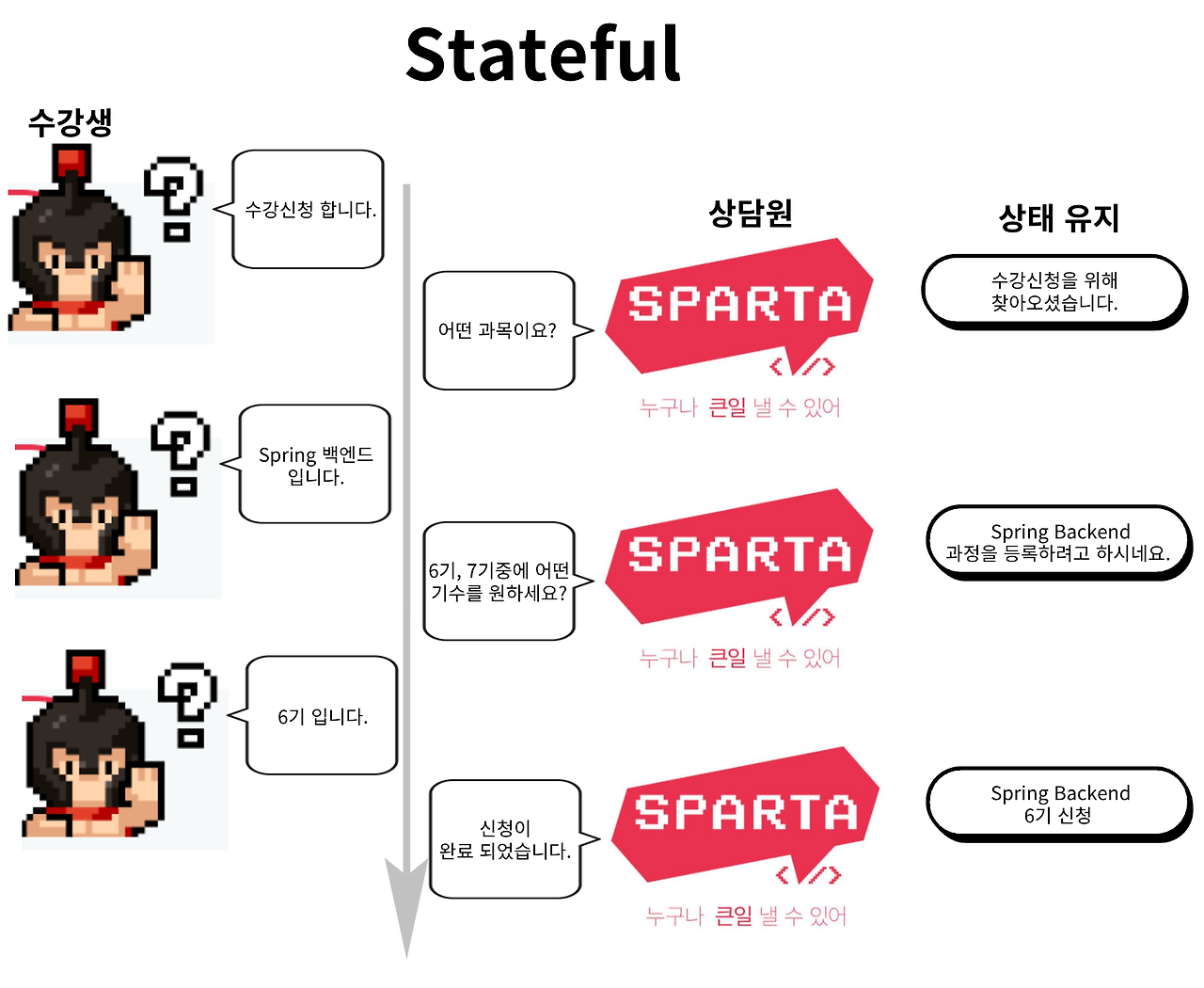
-클라이언트는 서버의 요청을 기억(상태유지)하여 다음 질문들에 대한 처리가 가능하다.
**Stateful 방식의 문제점
-같은 서버가 유지되어야한다.
-상태를 유지하고 있던 서버가 종료된다면 사용할 수 없게 됨.

-서버는 다양한 이유로 동작하지 않을 수 있다.
→시스템 에러, 비지니스 로직 문제, 리소스 부족 문제 등
-요청 트래픽이 몰리게 되면 상태를 유지하는 것에 Resource가 많이 소모된다.
→리소스가 버티지 못하면 서버가 종료되거나, 다음 요청에 대한 처리가 느려진다.
*Stateless -무상태
-클라이언트의 상태를 유지하지 않는다.

-다른 직원이 와서 상담을 해도 수강신청을 할 수 있다.
**Stateless 방식의 장단점

<장점>
-같은 서버를 유지할 필요가 없다.
-Scale Out 수평 확장성이 높다.
-갑자기 요청량이 증가해도 서버를 증설하기 쉽다.
<단점>
-클라이언트가 데이터를 추가적으로 전송해야한다.
-전송되는 데이터 양이 많아진다.
**Stateless 방식의 한계점
-WebApplication을 만들 때 서버의 확장성을 고려하여 최대한 Stateless 하게 만들어야 한다.
-실제로는 로그인과 같은 상태를 유지해야하는 경우가 발생한다.
-Cookie, Session, Token 등을 활용하여 이러한 한계를 극복한다.
→상태 유지를 최소화 시켜야한다.
5. Connection, Connectionless
-클라이언트와 서버 간의 연결 유지 여부에 따라 나뉘는 특성
*Connection -연결

-서버는 클라이언트와 연결을 유지하기 위해서 자원을 소모한다.
-수많은 사람들이 서비스를 이용해도 실제 서버에서 동시에 처리하는 요청은 작다.
→클라이언트 2,3이 아무런 요청이 없어도 연결을 유지한다.
**Connection 장단점
<장점>
-새로운 연결 과정을 거치지 않아도 된다.
-요청에 대한 응답 속도가 빨라진다.
<단점>
-클라이언트가 지속적으로 요청을 보낼거라는 보장이 없다.
-연결을 위한 자원이 낭비된다.
*Connectionless -비연결

-클라이언트와 서버는 연결을 유지하지 않는다.
-서버는 최소한의 자원만을 사용한다.
→브라우저가 켜진 상태에서 인터넷이 종료되어도 홈페이지가 정상적으로 노출된다.
**Connectionless 장단점
<장점>
-서버 자원을 효율적으로 사용할 수 있다.
<단점>
-요청이 추가적으로 오게 되면 연결(3 way handshake)을 새로 해야한다.
→요청에 대한 응답시간이 증가한다.
-웹 사이트의 HTML, CSS, JS, 이미지 등의 정적 자원을 모두 다시 다운로드 한다.
→캐시, 브라우저 캐싱으로 해결한다. =임시저장
-현재는 HTTP 지속연결(Persistent Connections)로 문제를 해결한다.
*HTTP 지속연결(Persistent Connections)

-하나의 요청에 필요한 요청들이 모두 응답될 때 까지 연결을 유지한다.
-연결을 한번만 맺고 끊기 때문에, Connectionless 방식보다 연결 횟수가 적다.
→그만큼 속도가 빨라졌다.
[TIL]
-강의 초반에 java, intelliJ, Git 설치를 해야한다고 해서 시작하자마자 난관에 부딪혔다. 전에 intelliJ와 Git을 설치할때도 맥os도 익숙하지 않은데다가 처음 들어보는 것들을 설치하려니 막막했고, 설명을 봐도 해결이 안되는 것들이 있어서 구글링을 통해 겨우겨우 설치했는데, 이번에는 또 java 설치와 intelliJ 설정변경을 해야했다. 그래도 git을 설치해봐서 java 설치는 금방 했는데, 하다보니까 git 설치할때 homebrew를 제대로 설치를 하지 않아서 그것도 다시 찾아서 설치했다. 어찌저찌 다 끝내고 intelliJ에 Gradle 버전을 맞추려고 했는데 잘 되지않아서 튜터님께 여쭤보러 갔더니 한번도 Gradle로 프로젝트를 생성한 적이 없어서 그렇다고 해결방법을 알려주셨다. 그래도 바로 가서 물어보기보단 여러방법을 찾아보고 가니까 조금 더 익숙해진 느낌이고 바로 알아들을 수 있어서 괜찮았던 것 같다.
-강의를 듣다보니 해저광케이블로 물리적인 연결이 있다는 걸 처음 알게 되었고, 가장 익숙하다고 생각했던 IP주소가 문제가 있다는 것도 알게 되었다. TCP라는 것이 IP의 문제점을 해결하기 위해 만들어졌다는 것을 알고나니 UDP나 PORT에 대해서도 조금 이해가 가는 것 같다. 그리고 이때까지 그냥 흘려봤던 사이트에도 일정한 규칙이 있었구나 라는 것을 알게 되었고, 각각의 의미가 뭔지에 대해서도 알게되니 사이트 주소들이 조금씩 눈에 보이기 시작하는 것 같다.
-과제를 하면서도 느꼈지만 프로그래밍에 맞는 명명규칙을 사용하면 코드가 조금 더 깔끔해지고 가독성도 좋아진다는 것을 알게 되었다. 그리고 그런 명명규칙을 다시 공부해보니 내가 적용하지 못한 부분도 많은 것 같아서 앞으로 코드를 짤 때 참고해서 적용해봐야겠다고 생각한다.
'내배캠 > Spring' 카테고리의 다른 글
| [내일배움캠프/백엔드] 기초 Spring 4주차 강의 (0) | 2024.11.06 |
|---|---|
| [내일배움캠프/백엔드] 기초 Spring 3주차 강의 (1) | 2024.11.05 |
| [내일배움캠프/백엔드] 기초 Spring 2주차 강의 (3) | 2024.11.04 |
| [내일배움캠프/백엔드] 기초 Spring 1주차 강의 3. Web Application (5) | 2024.10.31 |
| [내일배움캠프/백엔드] 기초 Spring 1주차 강의 2. HTTP (4) | 2024.10.30 |